Over a decade ago I wrote a PHP-based podcast publishing/archive system. The idea behind it was MP3-first: no DB, no complications – just drop an MP3 file into a folder and distribute. The software could generate HTML and an iTunes RSS feed. The main point was simplicity and zero maintenance.
Over the last 10 years, a few issues cropped up. Some were fixed, and a couple of upgrades were slapped on top. However, a few issues (some major ones) remained, and last year I decided to rethink and rewrite the software.
No dream survives contact with reality
The rethinking phase was quite an enjoyable trip. Like a little kid in a candy shop, I was dreaming up anything and everything: rewrite in Java, JS, or Go; add a fancy frontend (to what purpose I wasn’t sure); p2p sync across servers; scaling; and so on.
Finally, the end of 2025 arrived, and it was time to get down to work. As pragmatism settled in, reality hit the fan: make it smaller, faster, and cheaper. Whatever it is, it must work on the smallest droplet, take as little space as possible, respond fast, and require no (or as little) maintenance as possible. With a countdown timer running, the feature set started to shrink rapidly.
Complexity & legacy
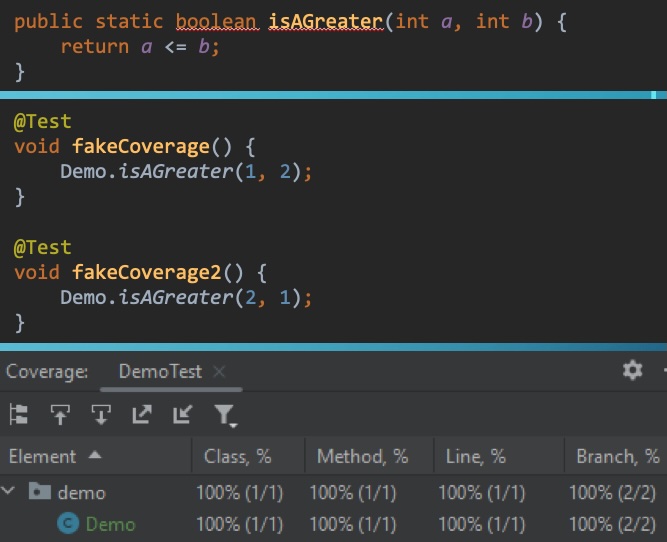
Next came a major design decision. A podcast is typically represented by an RSS feed (an XML file), which contains podcast information, a list of episodes, information about each episode, and a URL to the media file. Podcast client software reads the feed and displays it in a beautiful interface, ready for your enjoyment.
But where is the information stored? The internet is full of podcast-oriented CMSs (content management systems), podcast plugins for CMSs, and podcast services. Most of those solutions have one problem: they split information across a database, file storage, and/or config files. As a result we get complexity and, more importantly to me, legacy.
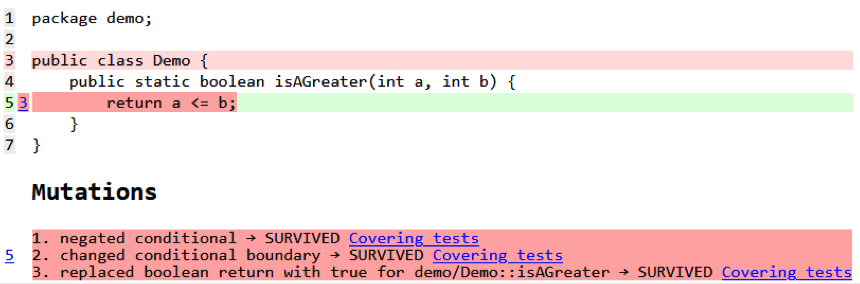
RSS feeds don’t grow infinitely. In theory they can, but in practice sooner or later the feed is trimmed and old episodes are forgotten. Well, not if I can help it – and wouldn’t it be nice to reduce system complexity at the same time?
Choose the source of truth
An audio recording (represented by an MP3 file) can be downloaded, stored, and listened to in any player (burn it to a CD for the old school). But most of the time it lacks the information provided by the RSS feed.
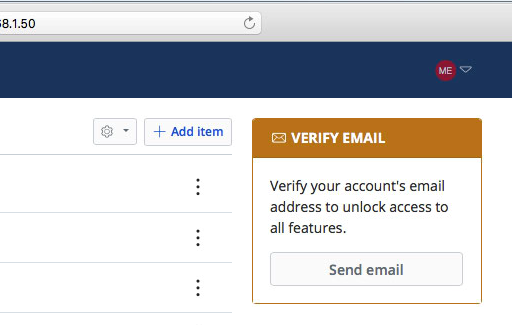
So what if we invert that? What if the source of truth is the MP3 file itself? All podcast information would be stored in the MP3: title, authors, show notes, and cover art. In that case, the RSS feed would simply reflect information already present in the MP3 file (episode).
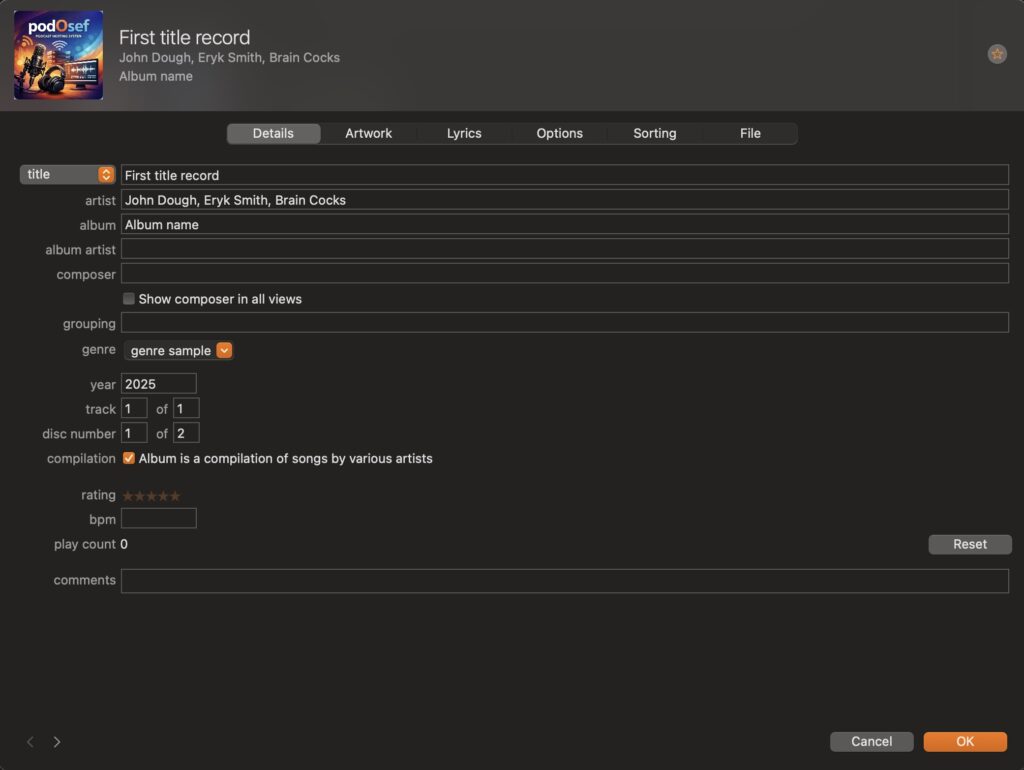
The Apple Music app lets you edit MP3 metadata (ID3 tags)
In such an arrangement, no database or metadata storage system is required. No need to monitor a DB, no need to back up metadata – almost everything you need is the MP3, since everything else can be recreated from the media file itself, plus a small config for Apple RSS feed requirements.
Make it as simple as possible and no simpler
The prior version was fully dynamic and, in retrospect, that didn’t make much sense, since RSS feeds typically don’t change often. Even if you release new episodes multiple times per day, a statically generated feed is still a far better fit and costs far less.
However, to avoid pauses and polling, the inotify utility was used. It effectively triggers regeneration on file changes, which avoids unnecessary polling and updates the RSS feed as soon as a new episode is uploaded.
Hugo – a static site generator – seemed like a good fit for the task. It’s small, fast, and supports RSS out of the box. In addition, Hugo turned out to be fairly easy to work with, even though I didn’t need much in the way of templating.
Next, it was time to deal with the source of truth. As far as MP3 goes, it has enough pockets to stash your information into. Different versions of software save metadata into different fields, so to accommodate them all – and make it as bulletproof as possible – ExifTool was chosen. It can read metadata from different media formats and write it into metadata files, which are then used by Hugo to generate HTML and RSS.
Main & archive
Now that complexity is addressed, let’s get back to legacy. As I mentioned before, sooner or later podcast episodes are trimmed and, well, lost – unless someone preserves them. In this case it’s fairly easy to organize an archival version of the podcast. Since all the information is contained within the MP3 file itself, all that’s left is to download it.
Taking this idea a little further: an archive can be organized simply by deploying PodOsef along with a downloader (already built). It literally watches the main RSS feed, downloads MP3s, and with a little configuration you’ve got yourself an archival (so to speak) version that keeps downloading new episodes and keeping old ones.
This can be used as a cheap form of scaling, or perhaps community-driven archiving. However, I haven’t put much thought into it, and I have a feeling there might be a better way to scale – but at what cost, I don’t know.
And so…
We got ourselves an MP3-first, simple, lightweight, cheap, minimalistic podcast publishing system – with an archival option – that’s containerized under 250 MB and can run on a small server/instance/droplet, or even on an old machine. PodOsef is open source. You can modify it as you see fit, or drop me feedback. While I can’t promise feature fulfillment, I sure do appreciate it. For more technical information, please go to the GitHub repo: https://github.com/meirka/podOsef