This article is dedicated to performance estimations and analysis of Atlassian Stash. Recently, I encountered performance issues with Stash – got the following banner on top of the website: “Atlassian Stash is reaching resource limits” and that, prompted questions about performance and possible solutions.
Note:
After initial log reviews, it was established that there are no issues or errors that might prevent Stash from optimal operation. In case of crashes or other issues with Stash, this article will not be helpful.
Data & Performance:
First get access to Stash’s access logs. Please note that log files might be broken into multiple parts so make sure to get them all. Example:
• atlassian-stash-access-2014-04-29.0.log
• atlassian-stash-access-2014-04-29.1.log
Next get “stash-log-parser” – https://bitbucket.org/ssaasen/stash-log-parser. It will go through logs and extract all the relevant information and as a bonus it can make a few very useful graphs.
Once you run the parser and get results, you can quickly review graphs and estimate where and when issues occur. Perhaps you have “automated building tools” that like to clone repos right in the middle of a workday and therefore are straining the server’s resources to the max.
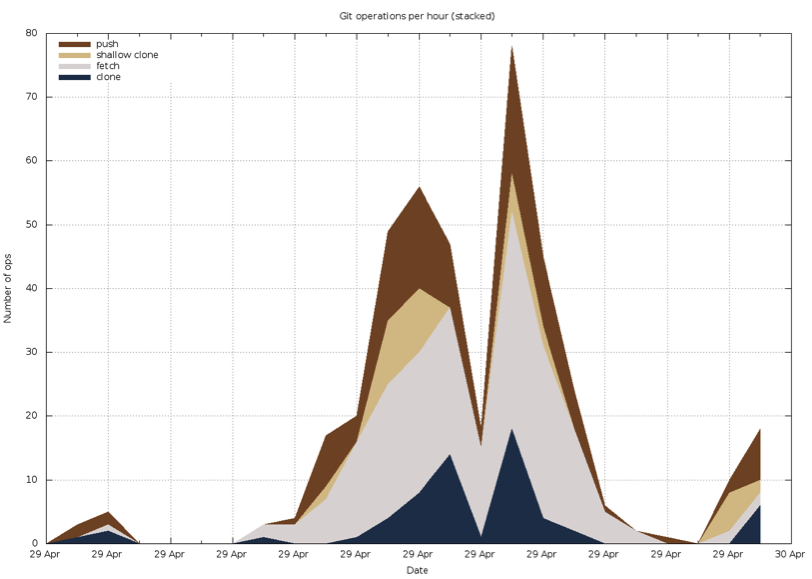
Next you will have to make a rough estimate of your usage and make sure that your machine has enough “juice” to pull the workload. First familiarize yourself with Stash’s “appetite”: https://confluence.atlassian.com/display/STASH/Scaling+Stash
Essentially rough estimates will come out to the following:
CPU requirements: number of CPUs = number of concurrent clone operations / 2
RAM requirements: amount of memory = 1.5 * number of concurrent clone operations * average repository size (if repository is larger than 700MB, then use 700MB for above calculation).
There are other GIT operations (besides clone), but clone is the most demanding one and therefore approximate system requirements are measured via “it”. So let’s take a look at the following examples:
Assume that you have a small setup with an average of 2 concurrent clones and repository sizes of about 5 MB, therefore you will need one CPU core and about 15MB of memory. Another case: you have around 10 concurrent clone requests with repository size of 2GB, therefore you will have to have CPU with at least 5 cores, and about 10.5GB of RAM.

Please note: that Stash itself doesn’t use the entire memory; instead it delegates GIT work to underlying GIT client that is installed in the operating system. Therefore you native GIT client will perform heavy lifting, allocating and de-allocating memory accordingly.
One more piece of advice with memory estimation – try to take an average size of actively used repositories. Stash might host several hundred repos, however active repositories might number only one hundred. In that case it would make sense to measure the average size of only active repos and calculate memory requirements based on that.
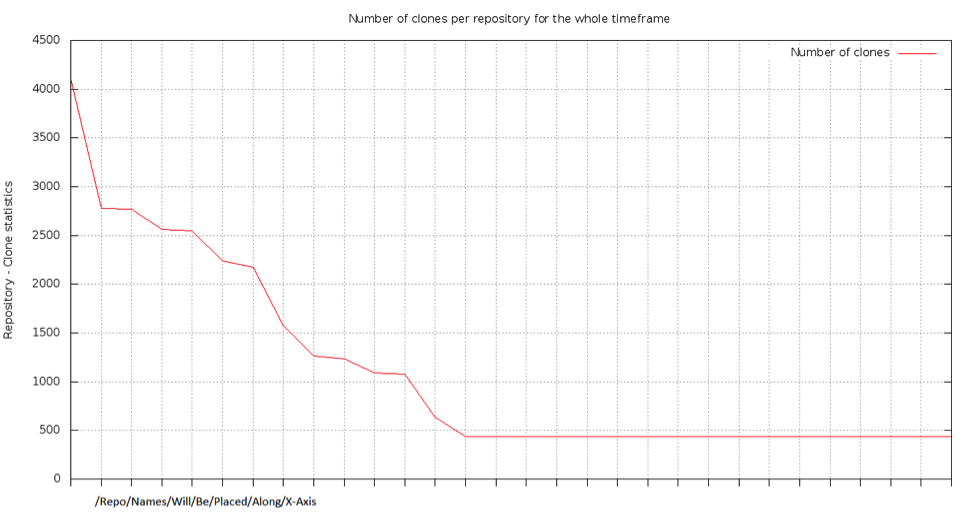
Also I would strongly encourage log accumulation (sometimes logs are not kept for more than a week) – that would allow having usage data for longer periods of time and therefore more accurately reflect usage and future needs.
Solutions:
There are a number of solutions that can be employed, in order to reduce workload and improve performance, however performance largely depends on a particular setup and usage scenario. Here are a couple of solutions:
1. Use SCM Cache Plugin in order to reduce cloning load on Stash (https://confluence.atlassian.com/display/STASH/Scaling+Stash)
2. Configure automatic build tools to use HTTP/HTTPS protocol
3. Configure hooks in Stash in order to notify automatic build tools of changes, instead of having automatic build tools pull data on a schedule – reducing number of requests
4. Re-schedule automatic build tools to run off peak hours
5. Upgrade hardware to estimated requirements