Не так давно я нашел довольно интересное видео о Transformation Priority Premise. Всем кто занимается/интересуется программированием смотреть!
Category: Software
Как настроить запись и прямое вещание для подкаста под OSX
Сегодня я решил посмотреть как настроить запись и прямой эфир подкаст с Audio HiJack.
Мои требования довольно простые:
– Вещать через Google Hangout или любой другой сервис
– Записывать аудио файл
– Держать скайп в готовности для гостей – возможность прийти в эфир в любой момент!
Тут нужно отметить что все описанные ниже настройки это абсолютный минимум и вы можете сами докрутить эффекты и приделать дополнительные повороты по вашим нуждам.
Необходимый софт:
– Audio HiJack 3
– Soundflower
Скачиваем и ставим. Далее открываем HiJack 3 и создаем новую чистую сессию. Теперь смотрим на картинку ниже и выстраиваем точную копию диаграммы.
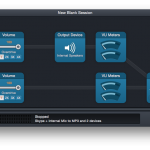
Далее можно включить Google Hangout или любой другой стрименговый сервис и указываем как input устройство Soundflower 2ch. Вот и все готово! Теперь нажав запись вы начинаете писать и вещать! Skype канал и микрофон сводятся после обработки ( можно так же добавить фильтры и эффекты ) и даже если скайп звонок отваливается то запись продолжается!
Performance analysis of Atlassian Stash
This article is dedicated to performance estimations and analysis of Atlassian Stash. Recently, I encountered performance issues with Stash – got the following banner on top of the website: “Atlassian Stash is reaching resource limits” and that, prompted questions about performance and possible solutions.
Note:
After initial log reviews, it was established that there are no issues or errors that might prevent Stash from optimal operation. In case of crashes or other issues with Stash, this article will not be helpful.
Data & Performance:
First get access to Stash’s access logs. Please note that log files might be broken into multiple parts so make sure to get them all. Example:
• atlassian-stash-access-2014-04-29.0.log
• atlassian-stash-access-2014-04-29.1.log
Next get “stash-log-parser” – https://bitbucket.org/ssaasen/stash-log-parser. It will go through logs and extract all the relevant information and as a bonus it can make a few very useful graphs.
Once you run the parser and get results, you can quickly review graphs and estimate where and when issues occur. Perhaps you have “automated building tools” that like to clone repos right in the middle of a workday and therefore are straining the server’s resources to the max.
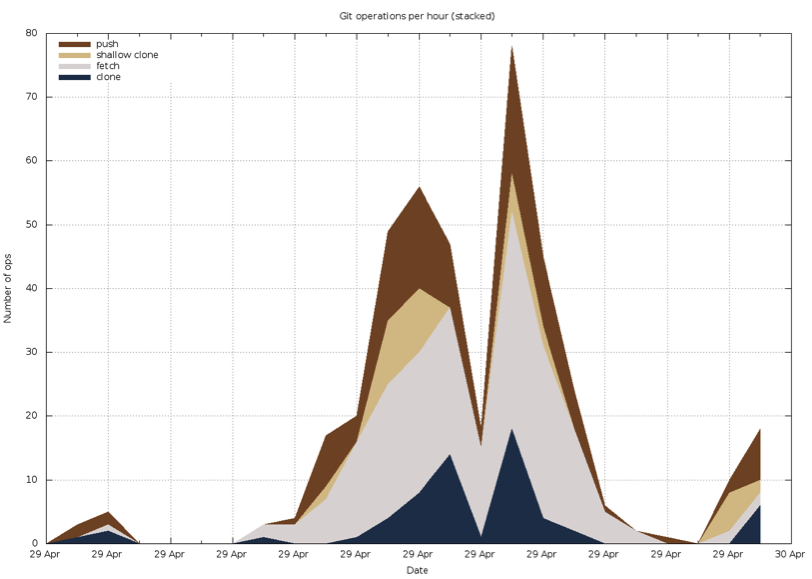
Next you will have to make a rough estimate of your usage and make sure that your machine has enough “juice” to pull the workload. First familiarize yourself with Stash’s “appetite”: https://confluence.atlassian.com/display/STASH/Scaling+Stash
Essentially rough estimates will come out to the following:
CPU requirements: number of CPUs = number of concurrent clone operations / 2
RAM requirements: amount of memory = 1.5 * number of concurrent clone operations * average repository size (if repository is larger than 700MB, then use 700MB for above calculation).
There are other GIT operations (besides clone), but clone is the most demanding one and therefore approximate system requirements are measured via “it”. So let’s take a look at the following examples:
Assume that you have a small setup with an average of 2 concurrent clones and repository sizes of about 5 MB, therefore you will need one CPU core and about 15MB of memory. Another case: you have around 10 concurrent clone requests with repository size of 2GB, therefore you will have to have CPU with at least 5 cores, and about 10.5GB of RAM.

Please note: that Stash itself doesn’t use the entire memory; instead it delegates GIT work to underlying GIT client that is installed in the operating system. Therefore you native GIT client will perform heavy lifting, allocating and de-allocating memory accordingly.
One more piece of advice with memory estimation – try to take an average size of actively used repositories. Stash might host several hundred repos, however active repositories might number only one hundred. In that case it would make sense to measure the average size of only active repos and calculate memory requirements based on that.
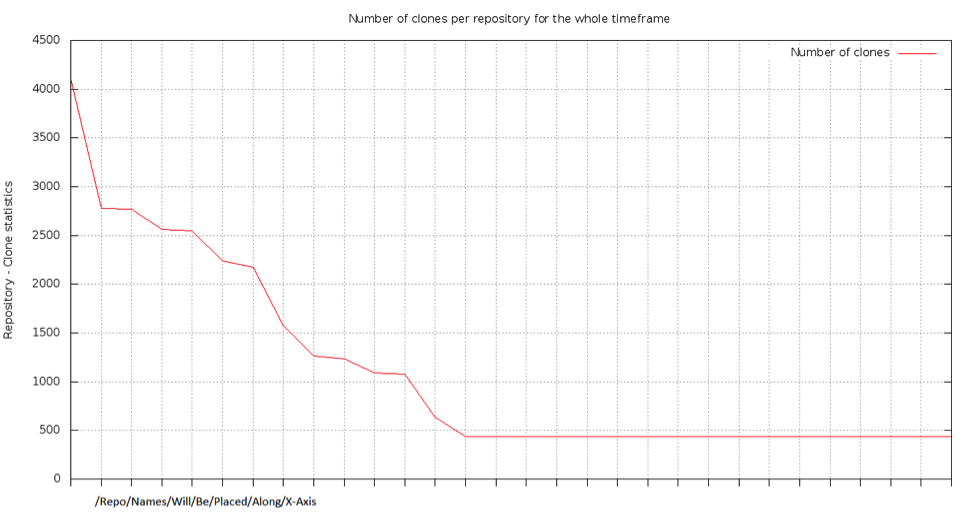
Also I would strongly encourage log accumulation (sometimes logs are not kept for more than a week) – that would allow having usage data for longer periods of time and therefore more accurately reflect usage and future needs.
Solutions:
There are a number of solutions that can be employed, in order to reduce workload and improve performance, however performance largely depends on a particular setup and usage scenario. Here are a couple of solutions:
1. Use SCM Cache Plugin in order to reduce cloning load on Stash (https://confluence.atlassian.com/display/STASH/Scaling+Stash)
2. Configure automatic build tools to use HTTP/HTTPS protocol
3. Configure hooks in Stash in order to notify automatic build tools of changes, instead of having automatic build tools pull data on a schedule – reducing number of requests
4. Re-schedule automatic build tools to run off peak hours
5. Upgrade hardware to estimated requirements
Менаджмент софтваре разработок
Случайно наткнулся на статью о менаджменте софтваре разработок от Лайнуса Торвольдса и скажу прямо – она мне понравилась. Всем кому интересная эта тема советую прочитать: Linus Torvalds’s Lessons on Software Development Management
PDF версия: Linus Torvalds’s Lessons on Software Development M…
Русский язык теперь поддерживается
Много лет назад когда я настраивал свой сервер я решил поставить Openfire за место iChat севера.
Openfire мне тогда понравился по нескольким причинам. Проект живо развивался, все было понятно ( где хранятся данные ), были платины для ICQ и MSN, да и вообще как-то ближе было чем непонятный iChat server.
Жил я с Openfire-ом долго и счастливо. Со временем я перестал использовать ICQ и MSN… и сталь больше общаться с Русско-говорящими людьми. При этом заметил один не приятный момент.
Одна замечательная фишка Jabber-а заключается в том что можно посылать сообщения в оффлайн. То есть даже если человек не присутствует то можно ему послать сообщение и он его получит позже, когда логниться в жаббер. У меня с этим были маленькие проблемы. Если кто-то шлет мне оффлайн сообщение на Русском языке, то я получаю его в вопросиках. Например: посылают “Привед”, получаю “??????”.
Сегодня я решил разобраться с этой проблемой раз и на всегда. На данный момент проблема решена, но я так и не понял что было не так. Я лазил по форумам, менял настройки базы данных и так далее, но ничего не помогало. В итоге я решил применить “финальное” решение – все стереть и поставить по новой. У Openfire-а есть замечательный плаги – он позволяет импортировать и экспортировать пользователей, вместе с их контактами и так далее.
В итоге я экспортнул всех пользователей, стер базу и саму программу, поставил все заного и импортул все обратно. Конечно настройки пришлось выставить заного, но у меня не так много “не стандартных” настроек.
Единственное что я решил сделать по другому, так это не использовать mySQL. Я решил использовать embedded базу – что не очень хорошо для большого количества пользователей, но поскольку у меня их не много то все тип-топ.
MV2Frm
Сегодня собрал ( на копи-пасте ) небольшой AppleScript. Идея довольно проста: есть фото-рамка, iPhoto и непродвинутый юзер. И так, как же можно перенести фотки из iPhoto в фото-рамку при это не объясняя как создавать альбомы, таскать файлы/фотки и что-то куда-то копировать?
Решение:
Сперва даем название фото-рамке ( точнее выносному диске ) = “FRAME”.
Этот шаг делается всего один раз для новой фото-рамки.

Далее идем в iPhoto, гуляем по фоткам и выбираем что нравиться! Как только видем фотографию которая понравилась, то в левом-верхнем углу ставим флажок.

После того как выбрали что душе угодно, то жмем на прогу ( ака AppleScript ) и все фотки с флажками начинают копироваться в выносной диск – рамку. Все фотки попадают в отдельную папку – “Flagged”. Нужно отметить что я вытираю все фотки/файлы в папке перед записью новых фоток. Это значит что если фотография более не флагнута, то и в рамке она более не появиться.

Далее отсоединяем рамку от USB дырки и наслаждаемся фосками.
Итого:
Простое решения на простую задачу. Некоторые могут сказать что мол и так все можно ручками перенести и сделать… или так же можно использовать export функцию в iPhoto. И я с ними соглашусь, но для не продвинутых пользователей это не так просто как кажется.
Вообще если кому нужен скриптик / программулик то качайте и пишите в комменты.
GIT тут
Ну вот и подошел к концу этот бешеный день – в смысле я закончил установку и отладку GIT-а на своем сервере. Процесс занял относительно долгое времени, так как я работал над этим не постоянно ( когда удавалось ) и в основном по выходным.
Но сегодня я закончил все что нужно для полноценной работы маленькой команды. Интересно отметить такую фишку как git-shell. Она встает за место пользовательского шела и позволяет только пользоваться git репозиториями, не давая при этом ни какого допуска к системе.
И все же GIT это интересная система. Я не знаю ещё довольно много, но как только осваиваешь пару-тройку базовых вещей начинаешь понимать на сколько Гит удобен и прост. Кому интересно я советую посмотреть эту книгу. Я её немного полистал и мне кажется что она довольно хорошая для получения базовых и практических знаний о Гите.
Думаю я остановлюсь тут, так как мне ещё много чего нужно выучить. У меня есть небольшая теоретическая база, а дальше нужно практиковаться и пополнять знания.
Чирз!
ЗЫ: Как ни странно, но я нашел готовые builds Гита даже под PPC для Mac OS X. Тут нужно заметить что сейчас не так много програм выпускается с поддержкой старого железа, но не стоит забывать что ещё не перевелись сервера на PPC.
Два микрофона и один гараж банд.
В четверг я еду в Торонто и пока я буду там, нужно по доброй традиции собраться и записать подкаст. Сегодня я ломал голову на тему как же записать подкаст с двух+ микрофонов в гаражбанде ( Garageband ). Помню как-то давно я смотрел как это делать, но как-то не досмотрел… Сегодня я вернулся обратно к этой задаче.
Сперва я думал что нужно ставить кучу софта и настраивать там все через одно место. Сразу скажу что все очень просто, хотя местами кажется что могли сделать и ещё проще. Но не буду жаловать, а перейду к тому как же настроить до 4-х микрофонов в Гаражбанде.
Начинаем с того что открываем “Audio MIDI Setup”, находиться эта красота в “/Applications/Utilities/Audio MIDI Setup”.

Как видим у меня есть два микрофона, один встроенный (первый по списку) второй внешний (подсоединяете через кабель). Гаражбанд к сожаления не дает возможности на прямую (через настройки) выбрать оба микрофона + на разные дорожки. Что бы делаем? Жмите кнопку “+”

И добавляете “Aggregate Device”. Справа вы увидите список, где можно выбрать микрофоны. Ставим галочки на против “Built-in Microphone” и “Built-it Input” или других вами выбранных микрофонов.

Больше ничего делать не надо – закрывайте программу и открывайте гаражбанд. Идем в настройки (Garageband -> Preferences) гаражбанда и выбираем “Aggregate Device” как “Audio Input”

Закрываем настрой и идем выставлять дорожки. Выбираем дорожку и жмем “view / hide track info”:

Далее из “Input Sources” выбираем “Stereo 1/2 (Aggregate Device)”. Далее выбираем вторую дорожку и проставляем там “Stereo 3/4 (Aggregate Device)”. После этого мы почти готовы записываться, все что осталось так это поставить что бы две дорожки записывались одновременно. Для этого идем (из меню) “Track -> Enable Multitrack Recordring”. Далее мы видем появились красные кнопочки:

Выбираем все трэки которые должны записываться, ну а дальше пишемся. Все просто и понятно – красота да и только.
Ладно кому интересно оставляйте комменты, а я побежал собираться.
Долбанный Апплет
Выходные пролетели и я даже не успел крякнуть. В принципе это наверное хорошо. Я много работал, правда пока что пользы мало… Вчера я доделал свой Java Applet – который должен транслировать видео с web камеры, но пару часов назад я обнаружил что там проблема.
Проблема состоит в том что Апплет транслирует какой-то мусор, то есть видно что там идет какое-то видео, но не в том разрешении и не то что нужно. Апплет вообще забавный зверь… с одной стороны удобный для некоторых задач, но с другой стороны слишком много головной боли. Вот так и у меня получается, что вроде все работает (Жава код под Эклипсом), а как только все это пакую в Апплет так сразу начинаются разные проблемы.
Сперва не правильно паковал – типо библиотек не хватало. Потом оказалось что Апплет нужно ещё и подписывать – да бы получить доступ к операционной системе (выполнение разных системных шняг). Ну а теперь походу что-то где-то опять не срабатывает и получается полный пипец. Меня на данный момент это так сильно раздражает что хочется на стены лесть. Я уж думал что все, камера снимает, алгоритм декодирует, все работает в браузере – отлично! Но нет…
Ладно пойду спать, утро вечера мудренее.
Чирз и главное не сдаваться.
Traq
После почти 2-х недель (вечерами и когда время было) поисков и почти попав в уныние я нашел проектировщик проектов который на мой взгляд подходит для моих задач и подходит по критериям.
Что я хотел?
– Простой и удобный
– Написан на PHP
– Быстрый
– Возможность иметь несколько проектов
– Milestones
– Поддержка репозиториев
На мое удивление под такое описание подходит не так много проектировщиков. Даже Matis который казался мне отличным кандидатом в последствии отпал из-за того что смотреть на него просто тошно.
В процессе поиска, мое внимание привлек Redmine который хорош, но я так и не смог поставить Ruby на свой сервер… а если говорить точнее то Руби уже стоит на сервере, но не той версии и не с тем Рейком и не с тем Джемом, а делать апдейт ему оказалось сплошным кошмаром. Я так и не смог найти “ставим Руби для ламеров” или 3rd party пакет или ещё что нить (кроме компиляции и изощрений) для PowerPC машин.
Итого поиски продолжались долго и “весело”. За это время я успел пересмотреть кучу разного софта и даже некоторые софтины поставил на сервер, но все было напрасно. То специфика приложения была не та, то выглядело не так… вообщем я почти сдался. Но сегодня я набрел на Traq ( http://traqproject.org/ ) – скажу что на первый взгляд это все то что я хотел. Приложение быстрое даже с моим дохлым интернетом, поддерживает много проектов (а так же milestones), простое и даже есть поддержка SVN репозиториев. Минус для меня тут пока что один, нету поддержки GIT, но если софта мне окончательно понравиться, то думаю можно будет дописать самому или кинуть программеру денег и пусть он допишет.
Думаю что если кто нить в поисках планировщика, то посмотрите на Traq и возможно это то что вам нужно. В любом случае заходите на сайт traqproject.org или смотрите github – https://github.com/nirix/traq
Я же пойду спать, уже почти 3 часа ночи, а завтра начну заполнять планировщик проектами и смотреть как да что.
Чирз!